Screaming Frog: przegląd funkcji w 2026 roku

Screaming Frog SEO Spider to desktopowy crawler, który skanuje witrynę tak samo jak robot wyszukiwarki i pokazuje wszystkie techniczne problemy SEO w jednej tabeli: zepsute linki, przekierowania, duplikaty Title, brakujące canonical, błędy hreflang, dane strukturalne i dziesiątki innych parametrów. W tym przeglądzie na 2026 rok omawiamy cały funkcjonał, wady i zalety, przypadki sprawdzania cookies oraz scenariusze, w których narzędzie naprawdę przydaje się specjaliście SEO.
Czym jest Screaming Frog SEO Spider
Screaming Frog SEO Spider to program-crawler do technicznego audytu SEO od brytyjskiej firmy Screaming Frog. Instaluje się na komputerze (Windows, macOS, Ubuntu) i przechodzi witrynę po linkach wewnętrznych, zbierając dane z każdego URL-a: kod odpowiedzi, nagłówki, metatagi, linki, obrazy, dyrektywy indeksowania i więcej. W istocie to „rentgen” witryny oczami robota wyszukiwarki.
W przeciwieństwie do usług chmurowych Screaming Frog działa lokalnie, więc nie zależysz od limitów serwera i możesz skanować nawet środowiska staging zamknięte przed indeksowaniem. Narzędzie stało się faktycznym standardem branżowym — używają go agencje SEO, specjaliści in-house i audytorzy techniczni na całym świecie.
Wideoprzegląd Screaming Frog
Zanim przejdziemy do szczegółowego omówienia funkcji, obejrzyj oficjalny wideoprzegląd możliwości Screaming Frog SEO Spider — pokazuje on interfejs i logikę działania crawlera:
Główny funkcjonał Screaming Frog
Screaming Frog pokrywa niemal całe spektrum zadań technicznego SEO. Poniżej kluczowe moduły, których specjalista używa najczęściej.
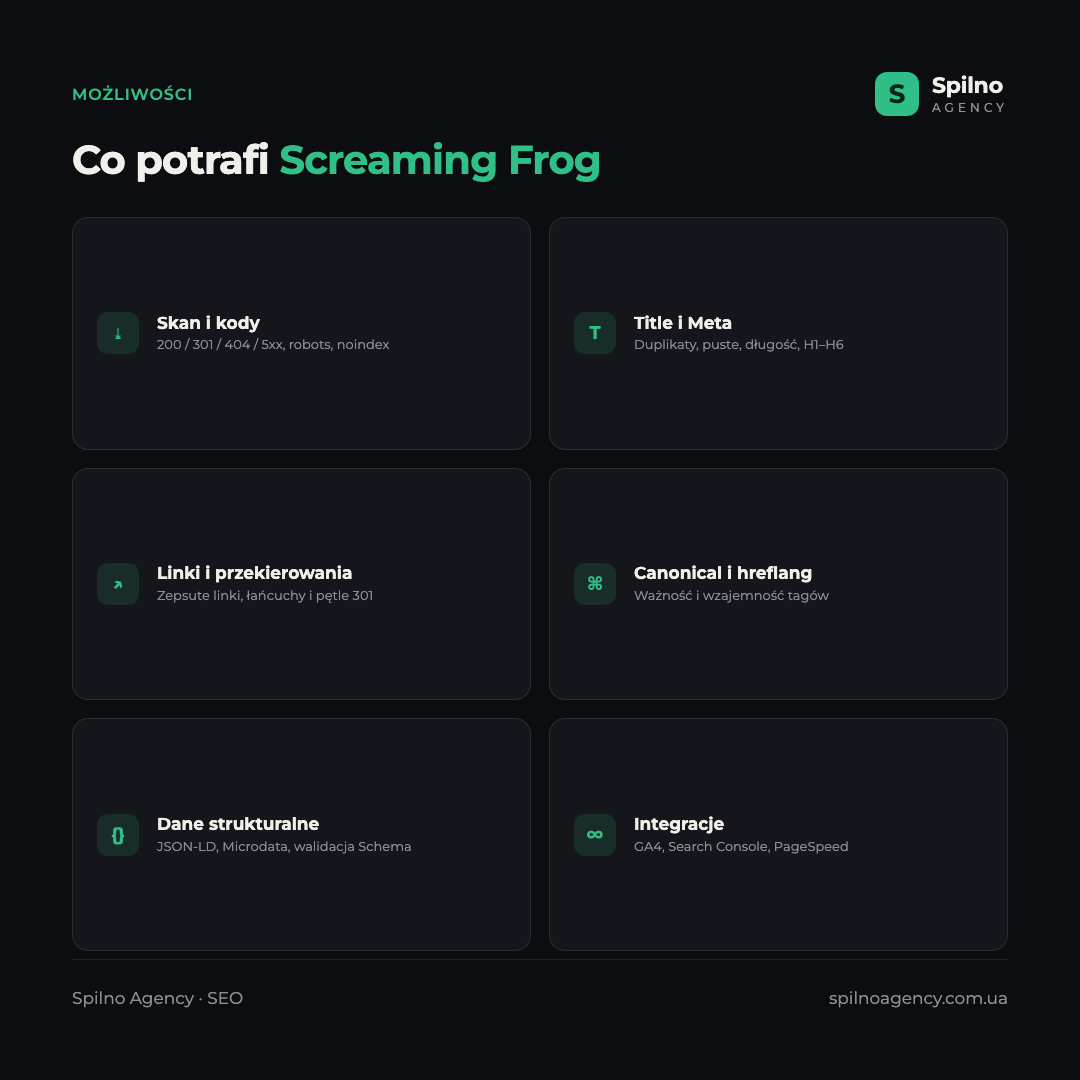
Skanowanie witryny i kody odpowiedzi
Funkcja podstawowa to przejście wszystkich URL-i i zapis kodu odpowiedzi serwera: 200 (OK), 301/302 (przekierowania), 404 (nie znaleziono), 5xx (błędy serwera). Od razu widzisz wszystkie zepsute linki, łańcuchy i pętle przekierowań oraz strony zablokowane w robots.txt lub dyrektywą noindex.
Title, Description i nagłówki H1–H6
Crawler zbiera wszystkie metatagi i nagłówki oraz podświetla problemy: puste lub zduplikowane Title, przekroczenie zalecanej długości, brakujące Description, kilka H1 na stronie. To najszybszy sposób na znalezienie masowych błędów w metadanych na dużej witrynie.
Duplikaty treści
Screaming Frog znajduje dokładne i przybliżone duplikaty stron za pomocą algorytmu porównywania treści, a także zduplikowane Title i Description. Pomaga to wykryć kanibalizację i strony, które „rozmywają” budżet indeksowania.
Obrazy i atrybuty alt
Narzędzie pokazuje obrazy bez atrybutu alt, zbyt „ciężkie” pliki i zepsute grafiki. Jest to przydatne zarówno dla SEO obrazów, jak i szybkości ładowania.
Canonical, hreflang i paginacja
Screaming Frog sprawdza poprawność tagów canonical, ważność i wzajemność (reciprocal) hreflang dla witryn wielojęzycznych oraz znaczniki paginacji. Błędy hreflang to jedna z najczęstszych przyczyn problemów projektów wielojęzycznych, a tutaj widać je od razu.
Dane strukturalne (Schema)
Crawler wyciąga znaczniki JSON-LD, Microdata i RDFa oraz waliduje je względem standardów Schema.org i wymagań Google. Można szybko sprawdzić, na których stronach są błędy w danych strukturalnych blokujące wyświetlanie rozszerzonych wyników.
XML Sitemap: generowanie i audyt
Screaming Frog potrafi wygenerować mapę witryny XML, a także porównać istniejący sitemap z rzeczywistą strukturą: znaleźć w mapie nieindeksowane lub 404 URL-e i odwrotnie — ważne strony, których w mapie brakuje.
Renderowanie JavaScript
Wersja płatna potrafi renderować strony przez wbudowany Chromium — tak jak robi to Googlebot. Jest to kluczowe dla witryn na React, Vue czy Angular: widzisz treść i linki, które pojawiają się dopiero po wykonaniu JavaScriptu.
Integracje: GA4, Search Console, PageSpeed
Crawler łączy się z Google Analytics 4, Search Console i API PageSpeed Insights, pobierając dane o ruchu, wyświetleniach, kliknięciach i Core Web Vitals prosto do tabeli obok parametrów technicznych. Dzięki temu widzisz nie tylko „gdzie jest błąd”, ale i „jak ważny jest pod względem ruchu”.
Custom Extraction (XPath / CSS)
Jedną z najpotężniejszych funkcji jest wybiórcze wyciąganie dowolnych danych ze stron za pomocą XPath, selektorów CSS lub regex: ceny, dostępność towaru, autorzy, daty, tagi. To w praktyce mini-parser wewnątrz crawlera SEO.
Analiza plików logów (Log File Analyser)
Osobny produkt Screaming Frog Log File Analyser pokazuje rzeczywiste zachowanie Googlebota na podstawie logów serwera: które URL-e i jak często skanuje robot oraz na co wydaje budżet indeksowania. To wyższy poziom audytu technicznego dla dużych witryn.
Przypadki sprawdzania cookies w Screaming Frog
Screaming Frog potrafi zapisywać i pokazywać cookies, które witryna ustawia podczas skanowania (funkcja Cookies w wersji płatnej). Dla specjalisty SEO i audytora otwiera to osobną warstwę zadań. Poniżej najpełniejsza lista przypadków, w których potrzebne jest sprawdzenie cookies.

- Audyt zgody (consent / RODO). Sprawdzenie, które cookies witryna ustawia jeszcze zanim użytkownik kliknie „Akceptuję” w banerze zgody — typowe naruszenie RODO i Consent Mode v2.
- Cookies przed zgodą (pre-consent). Znalezienie cookies analitycznych i reklamowych (np.
_ga,_gcl_au,_fbp) ustawianych bez pozwolenia — ryzyko kar i zniekształcenia danych. - Audyt cookies third-party. Sporządzenie pełnej listy cookies zewnętrznych (sieci reklamowe, widżety, czaty) na wszystkich stronach, by ocenić wpływ na prywatność i szybkość.
- Audyt pikseli śledzących. Wykrycie, gdzie uruchamiają się Meta Pixel, Google Ads, TikTok i inne tagi — i czy nie ma ich tam, gdzie być nie powinno.
- Wykrywanie cloakingu i treści zależnej od cookies. Porównanie, jak witryna serwuje treść z cookies i bez nich, by wychwycić ukrywanie treści przed robotem.
- Dostęp do treści za logowaniem. Ustawienie cookies autoryzacji, by przeskanować zamknięte sekcje (panel klienta, treść płatna) oczami zalogowanego użytkownika.
- Przekierowania zależne od cookies. Sprawdzenie, czy logika przekierowań nie zależy od cookies (np. przekierowania geo lub językowe), co może zmylić robota.
- Zbędne lub „ciężkie” cookies. Znalezienie nadmiaru cookies zwiększającego rozmiar żądań i wpływającego na wydajność.
- Weryfikacja po wdrożeniu. Po aktualizacji banera CMP lub menedżera tagów upewnienie się, że zachowanie cookies nie zmieniło się na gorsze.
Wersja darmowa i płatna
Screaming Frog ma dwie wersje. Darmowa pozwala skanować do 500 URL na jeden crawl i ma ograniczony zestaw funkcji — wystarczy dla małych witryn i podstawowego sprawdzenia. Płatna licencja roczna znosi limit URL i odblokowuje renderowanie JavaScript, integracje, custom extraction, zapis cookies, harmonogram i porównywanie crawli.
Licencja sprzedawana jest w modelu rocznej subskrypcji na jednego użytkownika. Dla agencji i specjalistów pracujących z dużymi witrynami wersja płatna zwraca się już przy pierwszym pełnym audycie. Nie warto pobierać „cracków” ani keygenów — to naruszenie licencji i ryzyko zainfekowania komputera roboczego.
Wady i zalety Screaming Frog
Jak każde narzędzie, Screaming Frog ma mocne i słabe strony. Oto uczciwe podsumowanie.
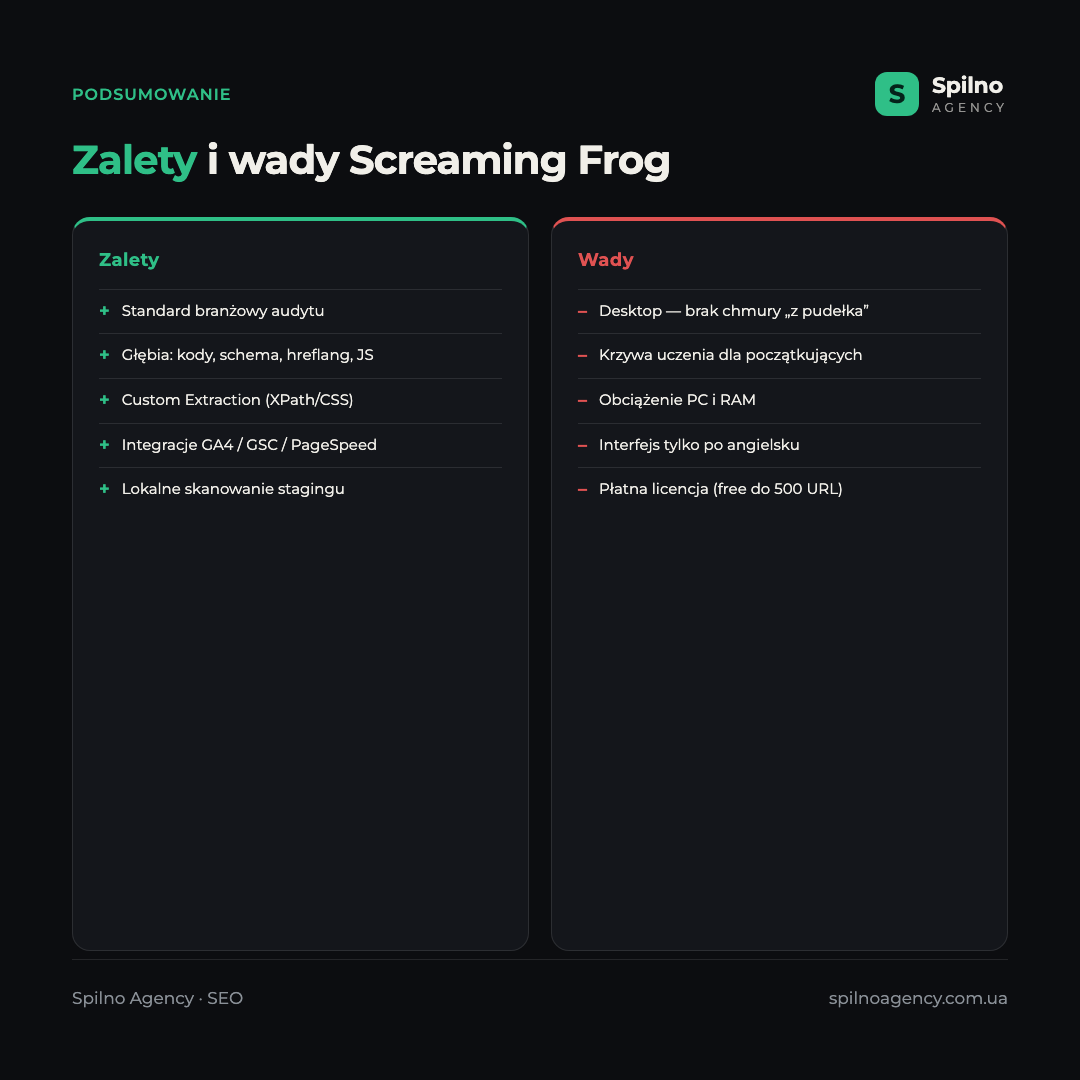
Zalety
- Standard branżowy — najpełniejszy zestaw technicznych kontroli SEO w jednym oknie.
- Głębia audytu — od kodów odpowiedzi po dane strukturalne, hreflang i renderowanie JS.
- Custom Extraction — elastyczne pobieranie dowolnych danych przez XPath/CSS/regex.
- Integracje z GA4, Search Console i PageSpeed — priorytetyzacja błędów wg ruchu.
- Praca lokalna — można skanować staging i witryny zamknięte przed indeksowaniem.
- Wersja darmowa do 500 URL na start i małe projekty.
Wady
- Aplikacja desktopowa — brak dostępu chmurowego i pracy zespołowej „z pudełka”.
- Krzywa uczenia — interfejs z dziesiątkami zakładek wydaje się początkującemu skomplikowany.
- Obciążenie PC — skanowanie dużych witryn wymaga dużo pamięci RAM.
- Interfejs po angielsku — brak oficjalnej lokalizacji.
- Płatna licencja dla pełnego funkcjonału (wersja darmowa ograniczona do 500 URL).
Przypadki użycia dla specjalisty SEO
Screaming Frog przydaje się w dziesiątkach scenariuszy. Oto najczęstsze zadania, które realizuje:
- Pełny techniczny audyt SEO witryny przed promocją.
- Znajdowanie i naprawa zepsutych linków (404) i łańcuchów przekierowań.
- Audyt metadanych: duplikaty i puste Title/Description na skalę.
- Kontrola migracji witryny: porównanie starych i nowych URL-i, mapa przekierowań 301.
- Sprawdzenie indeksowania:
noindex, canonical, robots.txt, dyrektywy. - Audyt hreflang w projektach wielojęzycznych.
- Walidacja danych strukturalnych przed uruchomieniem rozszerzonych wyników.
- Generowanie i audyt mapy witryny XML.
- Pobieranie danych konkurencji i własnej witryny przez Custom Extraction.
- Znajdowanie duplikatów treści i kanibalizacji.
- Audyt szybkości i Core Web Vitals przez integrację z PageSpeed.
- Sprawdzanie cookies i banerów zgody (zob. sekcja powyżej).
- Kontrola linkowania wewnętrznego i głębokości zagnieżdżenia stron.
Screaming Frog a crawlery chmurowe
Screaming Frog to crawler desktopowy, podczas gdy Sitebulb, JetOctopus czy Ahrefs Site Audit działają w chmurze. Rozwiązania chmurowe są wygodniejsze do regularnego monitoringu i pracy zespołowej, dają wizualizacje i przechowują historię bez obciążania PC. Z kolei Screaming Frog daje maksymalną elastyczność, głębię i kontrolę oraz możliwość skanowania środowisk lokalnych i zamkniętych. W praktyce doświadczeni specjaliści używają połączenia: Screaming Frog do głębokich, jednorazowych audytów i crawlera chmurowego do stałego monitoringu.
Najczęściej zadawane pytania (FAQ)
Czy Screaming Frog jest darmowy?
Tak, jest wersja darmowa z limitem 500 URL na crawl i ograniczonym zestawem funkcji. Dla pełnego funkcjonału (renderowanie JS, integracje, custom extraction, cookies) potrzebna jest płatna licencja roczna.
Do czego służy Screaming Frog?
Do technicznego audytu SEO: znajdowania zepsutych linków, przekierowań, duplikatów Title, błędów canonical i hreflang, sprawdzania danych strukturalnych, generowania map witryny i pobierania danych. To podstawowe narzędzie technicznego specjalisty SEO.
Czy w Screaming Frog można sprawdzać cookies?
Tak, wersja płatna zapisuje cookies, które witryna ustawia podczas skanowania. Wykorzystuje się to do audytu zgody (RODO), znajdowania cookies przed zgodą, audytu zewnętrznych trackerów i dostępu do treści za logowaniem.
Czy Screaming Frog renderuje JavaScript?
Tak, wersja płatna renderuje przez wbudowany Chromium. Pozwala to poprawnie skanować witryny na React, Vue i Angular, gdzie treść pojawia się po wykonaniu JavaScriptu.
Ile URL-i skanuje wersja darmowa?
Wersja darmowa jest ograniczona do 500 URL na crawl. Dla większych witryn potrzebna jest licencja płatna, która znosi to ograniczenie.
Screaming Frog to narzędzie, które powinno znaleźć się w arsenale każdego technicznego specjalisty SEO. Ale sam crawler nie poprawia pozycji: liczy się prawidłowa interpretacja danych i priorytetyzacja poprawek. Jeśli potrzebujesz głębokiego audytu technicznego witryny i jasnego planu działania, zespół Spilno Agency przeprowadzi pełną diagnozę i pomoże usunąć błędy hamujące wzrost ruchu.
Czytaj również
Atrybuty ARIA: co to jest i czy wpływają na SEO?
Atrybuty ARIA (od WAI-ARIA — Accessible Rich Internet Applications) to specjalne atrybuty HTML, takie jak aria-label, aria-labelledby czy…
WebMCP: co to jest i jak działa
WebMCP (Web Model Context Protocol) to nowy standard, który pozwala witrynie udostępnić agentom AI gotowe „narzędzia” do działań…

Consent Mode: jak prywatność danych wpływa na SEO w 2026 roku
Consent Mode (tryb zgody) to mechanizm, który zmienia działanie tagów analitycznych i reklamowych w zależności od tego, czy…