Screaming Frog: огляд функціоналу в 2026 році

Screaming Frog SEO Spider — це десктопний краулер, який сканує сайт так само, як це робить пошуковий робот, і показує всі технічні проблеми SEO в одній таблиці: биті посилання, редіректи, дублі Title, відсутні canonical, помилки hreflang, структуровані дані та десятки інших параметрів. У цьому огляді 2026 року розбираємо весь функціонал, плюси й мінуси, кейси перевірки cookies та сценарії, коли інструмент справді потрібен SEO-фахівцю.
Що таке Screaming Frog SEO Spider
Screaming Frog SEO Spider — це програма-краулер для технічного SEO-аудиту від британської компанії Screaming Frog. Вона встановлюється на комп’ютер (Windows, macOS, Ubuntu) і обходить сайт за внутрішніми посиланнями, збираючи дані з кожного URL: код відповіді, заголовки, метатеги, посилання, зображення, директиви індексації тощо. По суті, це «рентген» сайту очима пошукового робота.
На відміну від хмарних сервісів, Screaming Frog працює локально, тому ви не залежите від лімітів сервера й можете сканувати навіть закриті від індексації стейджинг-середовища. Інструмент став фактичним галузевим стандартом: його використовують SEO-агенції, інхаус-фахівці та технічні аудитори по всьому світу.
Відеоогляд Screaming Frog
Перед тим як перейти до детального розбору функцій, подивіться офіційний відеоогляд можливостей Screaming Frog SEO Spider — він наочно показує інтерфейс і логіку роботи краулера:
Основний функціонал Screaming Frog
Screaming Frog закриває майже весь спектр завдань технічного SEO. Нижче — ключові модулі, які найчастіше використовує фахівець.

Сканування сайту і коди відповіді
Базова функція — обхід усіх URL і фіксація коду відповіді сервера: 200 (ОК), 301/302 (редіректи), 404 (не знайдено), 5xx (помилки сервера). Ви одразу бачите всі биті посилання, ланцюжки й цикли редіректів, а також сторінки, заблоковані в robots.txt чи директивою noindex.
Title, Description і заголовки H1–H6
Краулер збирає всі метатеги й заголовки та підсвічує проблеми: порожні або задубльовані Title, перевищення рекомендованої довжини, відсутні Description, кілька H1 на сторінці. Це найшвидший спосіб знайти масові помилки в метаданих на великому сайті.
Дублікати контенту
Screaming Frog знаходить точні й нечіткі дублі сторінок за алгоритмом порівняння контенту, а також задубльовані Title й Description. Це допомагає виявити канібалізацію та сторінки, які «розмивають» краулінговий бюджет.
Зображення та alt-тексти
Інструмент показує зображення без атрибута alt, занадто «важкі» файли та биті картинки. Це корисно і для SEO зображень, і для швидкості завантаження.
Canonical, hreflang і пагінація
Screaming Frog перевіряє коректність тегів canonical, валідність і взаємність (reciprocal) hreflang для багатомовних сайтів, а також розмітку пагінації. Помилки hreflang — одна з найчастіших причин проблем мультимовних проєктів, і тут їх видно одразу.
Структуровані дані (Schema)
Краулер витягує розмітку JSON-LD, Microdata й RDFa та валідує її за стандартами Schema.org і вимогами Google. Можна швидко перевірити, на яких сторінках є помилки в структурованих даних, що блокують показ розширених сніпетів.
XML Sitemap: генерація й аудит
Screaming Frog уміє генерувати XML-карту сайту, а також звіряти наявний sitemap із реальною структурою: знаходити в карті неіндексовані чи 404-URL і, навпаки, важливі сторінки, яких у карті немає.
JavaScript-рендеринг
Платна версія вміє рендерити сторінки через вбудований Chromium — як це робить Googlebot. Це критично для сайтів на React, Vue чи Angular: ви бачите контент і посилання, які з’являються лише після виконання JavaScript.
Інтеграції: GA4, Search Console, PageSpeed
Краулер підключається до Google Analytics 4, Search Console і PageSpeed Insights API, підтягуючи дані про трафік, покази, кліки та Core Web Vitals прямо в таблицю поряд із технічними параметрами. Так ви бачите не лише «де помилка», а й «наскільки вона важлива за трафіком».
Custom Extraction (XPath / CSS)
Одна з найпотужніших функцій — вибіркове витягування будь-яких даних зі сторінок за допомогою XPath, CSS-селекторів чи regex: ціни, наявність товару, авторів, дати, теги. Фактично це міні-парсер усередині SEO-краулера.
Аналіз лог-файлів (Log File Analyser)
Окремий продукт Screaming Frog Log File Analyser показує реальну поведінку Googlebot за серверними логами: які URL і як часто сканує робот, на що він витрачає краулінговий бюджет. Це вищий рівень технічного аудиту для великих сайтів.
Кейси перевірки cookies через Screaming Frog
Screaming Frog уміє зберігати й показувати cookies, які встановлює сайт під час сканування (функція Cookies у платній версії). Для SEO-фахівця та аудитора це відкриває окремий пласт завдань. Нижче — максимально повний перелік кейсів, коли потрібна перевірка cookies.

- Аудит згоди (consent / GDPR). Перевірити, які cookies сайт встановлює ще до того, як користувач натиснув «Прийняти» в банері згоди — типове порушення GDPR і Consent Mode v2.
- Cookies до згоди (pre-consent). Знайти аналітичні й рекламні cookies (наприклад
_ga,_gcl_au,_fbp), що ставляться без дозволу, — ризик штрафів і спотворення даних. - Аудит third-party cookies. Скласти повний перелік сторонніх cookies (рекламні мережі, віджети, чати) на всіх сторінках — щоб оцінити вплив на приватність і швидкість.
- Аудит трекінг-пікселів. Виявити, де спрацьовують Meta Pixel, Google Ads, TikTok та інші теги — і чи немає їх там, де не повинно бути.
- Виявлення клоакінгу й cookie-залежного контенту. Порівняти, як сайт віддає контент із cookies й без них — щоб помітити приховування контенту від робота.
- Доступ до контенту за логіном. Налаштувати cookies авторизації, щоб просканувати закриті розділи (особистий кабінет, платний контент) очима залогіненого користувача.
- Cookie-залежні редіректи. Перевірити, чи не залежить логіка редіректів від cookies (наприклад, гео- або мовні переадресації), що може заплутати пошукового робота.
- Зайві або «важкі» cookies. Знайти надлишок cookies, що збільшує розмір запитів і впливає на продуктивність.
- Перевірка після релізу. Після оновлення CMP-банера чи тег-менеджера переконатися, що поведінка cookies не змінилася в гірший бік.
Безкоштовна та платна версії
Screaming Frog має дві версії. Безкоштовна дозволяє сканувати до 500 URL за один краул і має обмежений набір функцій — її достатньо для невеликих сайтів і базової перевірки. Платна річна ліцензія знімає ліміт URL і відкриває JavaScript-рендеринг, інтеграції, custom extraction, збереження cookies, планувальник і порівняння краулів.
Ліцензія оформлюється за моделлю річної передплати на одного користувача. Для агенцій і фахівців, що працюють із великими сайтами, платна версія окупається вже на першому повноцінному аудиті. Завантажувати «кряки» чи кейгени не варто — це порушення ліцензії та ризик зараження робочого комп’ютера.
Плюси та мінуси Screaming Frog
Як і будь-який інструмент, Screaming Frog має сильні й слабкі сторони. Ось чесний підсумок.
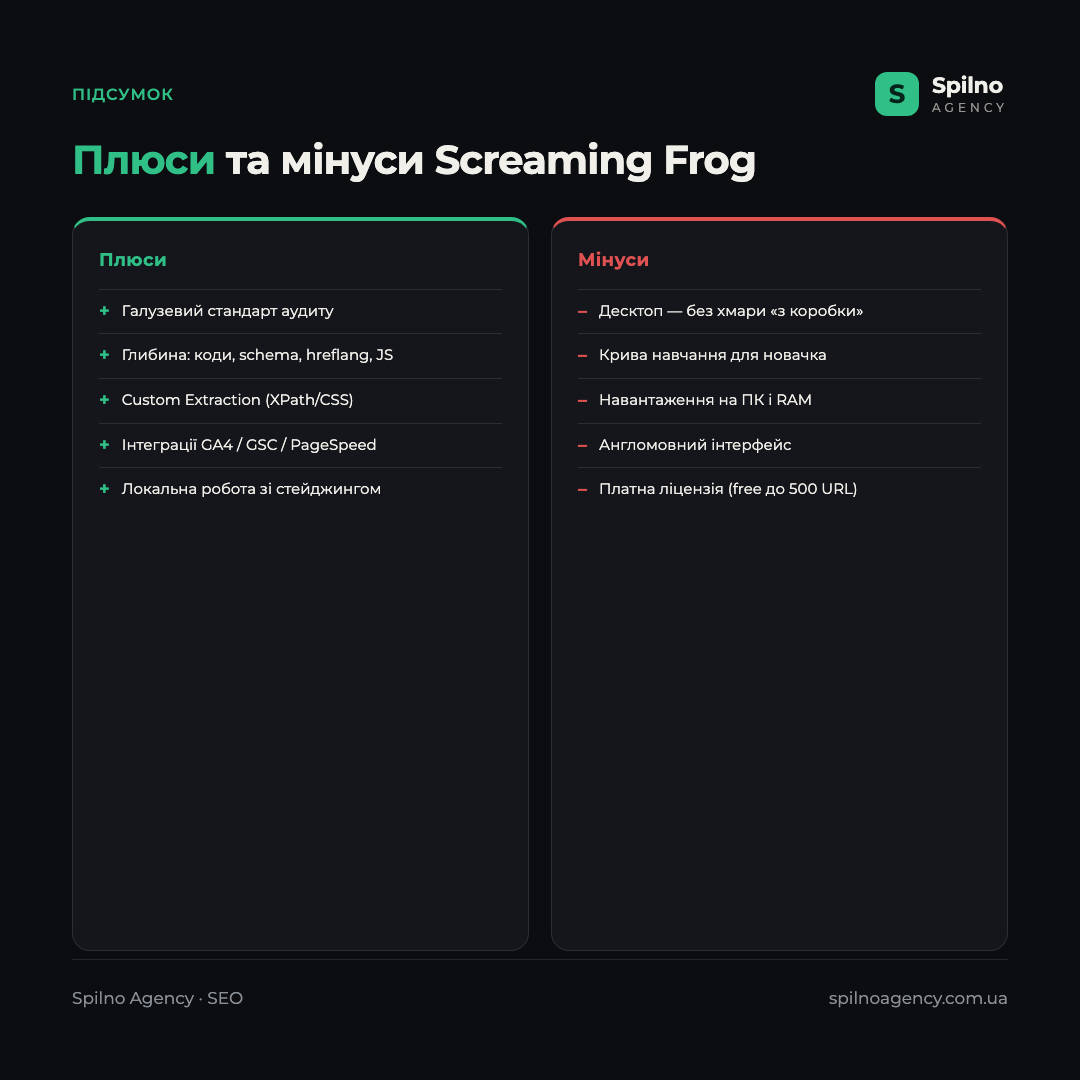
Плюси
- Галузевий стандарт — найповніший набір технічних SEO-перевірок в одному вікні.
- Глибина аудиту — від кодів відповіді до структурованих даних, hreflang і рендерингу JS.
- Custom Extraction — гнучкий парсинг будь-яких даних за XPath/CSS/regex.
- Інтеграції з GA4, Search Console і PageSpeed — пріоритезація помилок за трафіком.
- Локальна робота — можна сканувати стейджинг і сайти, закриті від індексації.
- Безкоштовна версія до 500 URL для старту й невеликих проєктів.
Мінуси
- Десктопна програма — немає хмарного доступу й командної роботи «з коробки».
- Крива навчання — новачку інтерфейс із десятками вкладок здається складним.
- Навантаження на ПК — сканування великих сайтів потребує багато оперативної пам’яті.
- Англомовний інтерфейс — немає офіційної української локалізації.
- Платна ліцензія для повного функціоналу (безкоштовна версія обмежена 500 URL).
Кейси використання для SEO-фахівця
Screaming Frog потрібен у десятках сценаріїв. Ось найчастіші завдання, які він закриває:
- Повний технічний SEO-аудит сайту перед просуванням.
- Пошук і виправлення битих посилань (404) та ланцюжків редіректів.
- Аудит метаданих: дублі й порожні Title/Description на масштабі.
- Контроль міграції сайту: звіряння старих і нових URL, мапа 301-редіректів.
- Перевірка індексації:
noindex, canonical, robots.txt, директиви. - Аудит hreflang на багатомовних проєктах.
- Валідація структурованих даних перед запуском розширених сніпетів.
- Генерація та аудит XML-карти сайту.
- Парсинг даних конкурентів і власного сайту через Custom Extraction.
- Пошук дублів контенту й канібалізації.
- Аудит швидкості й Core Web Vitals через інтеграцію з PageSpeed.
- Перевірка cookies та консент-банерів (див. блок вище).
- Контроль внутрішньої перелінковки й глибини вкладеності сторінок.
Screaming Frog vs хмарні краулери
Screaming Frog — десктопний краулер, тоді як Sitebulb, JetOctopus чи Ahrefs Site Audit працюють у хмарі. Хмарні рішення зручніші для регулярного моніторингу й командної роботи, дають візуалізації та зберігають історію без навантаження на ваш ПК. Натомість Screaming Frog дає максимальну гнучкість, глибину й контроль, а також можливість сканувати локальні та закриті середовища. На практиці досвідчені фахівці використовують зв’язку: Screaming Frog — для глибокого разового аудиту, хмарний краулер — для постійного моніторингу.
Часті запитання (FAQ)
Чи безкоштовний Screaming Frog?
Так, є безкоштовна версія з лімітом 500 URL за один краул і обмеженим набором функцій. Для повного функціоналу (JS-рендеринг, інтеграції, custom extraction, cookies) потрібна платна річна ліцензія.
Для чого потрібен Screaming Frog?
Для технічного SEO-аудиту: пошуку битих посилань, редіректів, дублів Title, помилок canonical і hreflang, перевірки структурованих даних, генерації sitemap і парсингу даних. Це базовий інструмент технічного SEO-фахівця.
Чи можна перевіряти cookies у Screaming Frog?
Так, платна версія зберігає cookies, які встановлює сайт під час сканування. Це використовують для аудиту згоди (GDPR), пошуку cookies до згоди, аудиту сторонніх трекерів і доступу до контенту за логіном.
Чи рендерить Screaming Frog JavaScript?
Так, у платній версії є рендеринг через вбудований Chromium. Це дозволяє коректно сканувати сайти на React, Vue й Angular, де контент з’являється після виконання JavaScript.
Скільки URL сканує безкоштовна версія?
Безкоштовна версія обмежена 500 URL за один краул. Для більших сайтів потрібна платна ліцензія, яка знімає це обмеження.
Screaming Frog — інструмент, який має бути в арсеналі кожного технічного SEO-фахівця. Але сам по собі краулер не покращує позиції: значення має правильна інтерпретація даних і пріоритезація виправлень. Якщо вам потрібен глибокий технічний аудит сайту й чіткий план дій, команда Spilno Agency проведе повну діагностику та допоможе усунути помилки, що стримують зростання трафіку.
Залишились питання?
Розкажіть про задачу — відповімо по темі статті
Читайте також
ARIA-мітки: що це таке і чи впливає на SEO?
ARIA-мітки (від WAI-ARIA — Accessible Rich Internet Applications) — це спеціальні HTML-атрибути, як-от aria-label, aria-labelledby чи role, які…

WebMCP: що це таке і як він працює
WebMCP (Web Model Context Protocol) — це новий стандарт, який дозволяє сайту надати AI-агенту готові «інструменти» для дій…

Режим згоди: як конфіденційність даних впливає на SEO в 2026 році
Режим згоди (Consent Mode) — це механізм, який змінює поведінку тегів аналітики й реклами залежно від того, чи…