Screaming Frog: обзор функционала в 2026 году

Screaming Frog SEO Spider — это десктопный краулер, который сканирует сайт так же, как это делает поисковый робот, и показывает все технические проблемы SEO в одной таблице: битые ссылки, редиректы, дубли Title, отсутствующие canonical, ошибки hreflang, структурированные данные и десятки других параметров. В этом обзоре 2026 года разбираем весь функционал, плюсы и минусы, кейсы проверки cookies и сценарии, когда инструмент действительно нужен SEO-специалисту.
Что такое Screaming Frog SEO Spider
Screaming Frog SEO Spider — это программа-краулер для технического SEO-аудита от британской компании Screaming Frog. Она устанавливается на компьютер (Windows, macOS, Ubuntu) и обходит сайт по внутренним ссылкам, собирая данные с каждого URL: код ответа, заголовки, метатеги, ссылки, изображения, директивы индексации и прочее. По сути, это «рентген» сайта глазами поискового робота.
В отличие от облачных сервисов, Screaming Frog работает локально, поэтому вы не зависите от лимитов сервера и можете сканировать даже закрытые от индексации стейджинг-среды. Инструмент стал фактическим отраслевым стандартом: его используют SEO-агентства, инхаус-специалисты и технические аудиторы по всему миру.
Видеообзор Screaming Frog
Прежде чем перейти к детальному разбору функций, посмотрите официальный видеообзор возможностей Screaming Frog SEO Spider — он наглядно показывает интерфейс и логику работы краулера:
Основной функционал Screaming Frog
Screaming Frog закрывает почти весь спектр задач технического SEO. Ниже — ключевые модули, которые чаще всего использует специалист.

Сканирование сайта и коды ответа
Базовая функция — обход всех URL и фиксация кода ответа сервера: 200 (ОК), 301/302 (редиректы), 404 (не найдено), 5xx (ошибки сервера). Вы сразу видите все битые ссылки, цепочки и циклы редиректов, а также страницы, заблокированные в robots.txt или директивой noindex.
Title, Description и заголовки H1–H6
Краулер собирает все метатеги и заголовки и подсвечивает проблемы: пустые или задублированные Title, превышение рекомендуемой длины, отсутствующие Description, несколько H1 на странице. Это самый быстрый способ найти массовые ошибки в метаданных на большом сайте.
Дубликаты контента
Screaming Frog находит точные и нечёткие дубли страниц по алгоритму сравнения контента, а также задублированные Title и Description. Это помогает выявить каннибализацию и страницы, которые «размывают» краулинговый бюджет.
Изображения и alt-тексты
Инструмент показывает изображения без атрибута alt, слишком «тяжёлые» файлы и битые картинки. Это полезно и для SEO изображений, и для скорости загрузки.
Canonical, hreflang и пагинация
Screaming Frog проверяет корректность тегов canonical, валидность и взаимность (reciprocal) hreflang для многоязычных сайтов, а также разметку пагинации. Ошибки hreflang — одна из самых частых причин проблем мультиязычных проектов, и здесь их видно сразу.
Структурированные данные (Schema)
Краулер извлекает разметку JSON-LD, Microdata и RDFa и валидирует её по стандартам Schema.org и требованиям Google. Можно быстро проверить, на каких страницах есть ошибки в структурированных данных, блокирующие показ расширенных сниппетов.
XML Sitemap: генерация и аудит
Screaming Frog умеет генерировать XML-карту сайта, а также сверять имеющийся sitemap с реальной структурой: находить в карте неиндексируемые или 404-URL и, наоборот, важные страницы, которых в карте нет.
JavaScript-рендеринг
Платная версия умеет рендерить страницы через встроенный Chromium — как это делает Googlebot. Это критично для сайтов на React, Vue или Angular: вы видите контент и ссылки, которые появляются только после выполнения JavaScript.
Интеграции: GA4, Search Console, PageSpeed
Краулер подключается к Google Analytics 4, Search Console и PageSpeed Insights API, подтягивая данные о трафике, показах, кликах и Core Web Vitals прямо в таблицу рядом с техническими параметрами. Так вы видите не только «где ошибка», но и «насколько она важна по трафику».
Custom Extraction (XPath / CSS)
Одна из самых мощных функций — выборочное извлечение любых данных со страниц с помощью XPath, CSS-селекторов или regex: цены, наличие товара, авторы, даты, теги. Фактически это мини-парсер внутри SEO-краулера.
Анализ лог-файлов (Log File Analyser)
Отдельный продукт Screaming Frog Log File Analyser показывает реальное поведение Googlebot по серверным логам: какие URL и как часто сканирует робот, на что он тратит краулинговый бюджет. Это более высокий уровень технического аудита для крупных сайтов.
Кейсы проверки cookies через Screaming Frog
Screaming Frog умеет сохранять и показывать cookies, которые устанавливает сайт во время сканирования (функция Cookies в платной версии). Для SEO-специалиста и аудитора это открывает отдельный пласт задач. Ниже — максимально полный перечень кейсов, когда нужна проверка cookies.

- Аудит согласия (consent / GDPR). Проверить, какие cookies сайт устанавливает ещё до того, как пользователь нажал «Принять» в баннере согласия — типичное нарушение GDPR и Consent Mode v2.
- Cookies до согласия (pre-consent). Найти аналитические и рекламные cookies (например
_ga,_gcl_au,_fbp), которые ставятся без разрешения, — риск штрафов и искажения данных. - Аудит third-party cookies. Составить полный перечень сторонних cookies (рекламные сети, виджеты, чаты) на всех страницах — чтобы оценить влияние на приватность и скорость.
- Аудит трекинг-пикселей. Выявить, где срабатывают Meta Pixel, Google Ads, TikTok и другие теги — и нет ли их там, где не должно быть.
- Выявление клоакинга и cookie-зависимого контента. Сравнить, как сайт отдаёт контент с cookies и без них — чтобы заметить сокрытие контента от робота.
- Доступ к контенту за логином. Настроить cookies авторизации, чтобы просканировать закрытые разделы (личный кабинет, платный контент) глазами залогиненного пользователя.
- Cookie-зависимые редиректы. Проверить, не зависит ли логика редиректов от cookies (например, гео- или языковые переадресации), что может запутать поискового робота.
- Лишние или «тяжёлые» cookies. Найти избыток cookies, увеличивающий размер запросов и влияющий на производительность.
- Проверка после релиза. После обновления CMP-баннера или тег-менеджера убедиться, что поведение cookies не изменилось в худшую сторону.
Бесплатная и платная версии
У Screaming Frog две версии. Бесплатная позволяет сканировать до 500 URL за один краул и имеет ограниченный набор функций — её достаточно для небольших сайтов и базовой проверки. Платная годовая лицензия снимает лимит URL и открывает JavaScript-рендеринг, интеграции, custom extraction, сохранение cookies, планировщик и сравнение краулов.
Лицензия оформляется по модели годовой подписки на одного пользователя. Для агентств и специалистов, работающих с крупными сайтами, платная версия окупается уже на первом полноценном аудите. Скачивать «краки» или кейгены не стоит — это нарушение лицензии и риск заражения рабочего компьютера.
Плюсы и минусы Screaming Frog
Как и любой инструмент, Screaming Frog имеет сильные и слабые стороны. Вот честный итог.
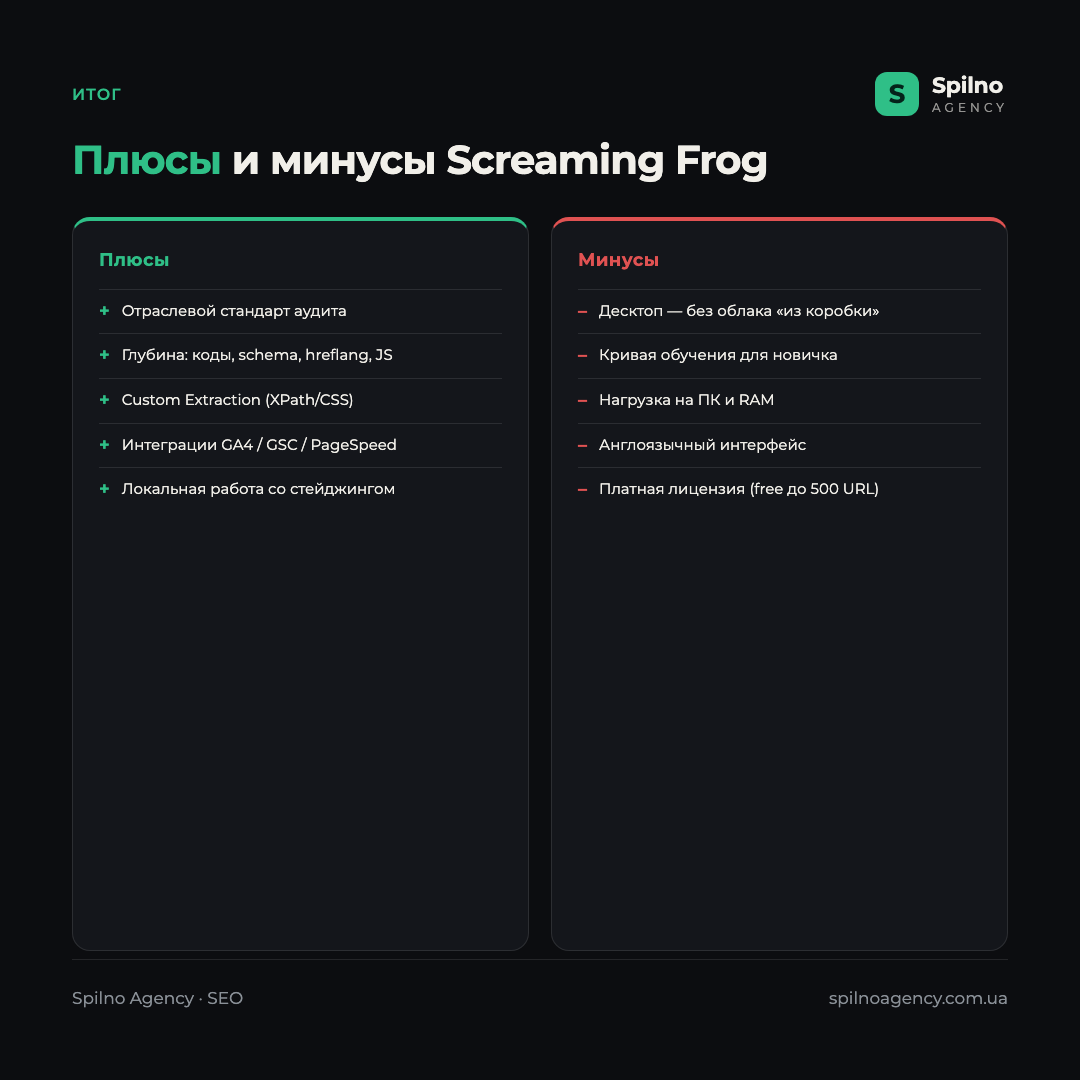
Плюсы
- Отраслевой стандарт — самый полный набор технических SEO-проверок в одном окне.
- Глубина аудита — от кодов ответа до структурированных данных, hreflang и рендеринга JS.
- Custom Extraction — гибкий парсинг любых данных по XPath/CSS/regex.
- Интеграции с GA4, Search Console и PageSpeed — приоритизация ошибок по трафику.
- Локальная работа — можно сканировать стейджинг и сайты, закрытые от индексации.
- Бесплатная версия до 500 URL для старта и небольших проектов.
Минусы
- Десктопная программа — нет облачного доступа и командной работы «из коробки».
- Кривая обучения — новичку интерфейс с десятками вкладок кажется сложным.
- Нагрузка на ПК — сканирование больших сайтов требует много оперативной памяти.
- Англоязычный интерфейс — нет официальной локализации.
- Платная лицензия для полного функционала (бесплатная версия ограничена 500 URL).
Кейсы использования для SEO-специалиста
Screaming Frog нужен в десятках сценариев. Вот самые частые задачи, которые он закрывает:
- Полный технический SEO-аудит сайта перед продвижением.
- Поиск и исправление битых ссылок (404) и цепочек редиректов.
- Аудит метаданных: дубли и пустые Title/Description на масштабе.
- Контроль миграции сайта: сверка старых и новых URL, карта 301-редиректов.
- Проверка индексации:
noindex, canonical, robots.txt, директивы. - Аудит hreflang на многоязычных проектах.
- Валидация структурированных данных перед запуском расширенных сниппетов.
- Генерация и аудит XML-карты сайта.
- Парсинг данных конкурентов и собственного сайта через Custom Extraction.
- Поиск дублей контента и каннибализации.
- Аудит скорости и Core Web Vitals через интеграцию с PageSpeed.
- Проверка cookies и консент-баннеров (см. блок выше).
- Контроль внутренней перелинковки и глубины вложенности страниц.
Screaming Frog vs облачные краулеры
Screaming Frog — десктопный краулер, тогда как Sitebulb, JetOctopus или Ahrefs Site Audit работают в облаке. Облачные решения удобнее для регулярного мониторинга и командной работы, дают визуализации и хранят историю без нагрузки на ваш ПК. Screaming Frog, в свою очередь, даёт максимальную гибкость, глубину и контроль, а также возможность сканировать локальные и закрытые среды. На практике опытные специалисты используют связку: Screaming Frog — для глубокого разового аудита, облачный краулер — для постоянного мониторинга.
Частые вопросы (FAQ)
Бесплатен ли Screaming Frog?
Да, есть бесплатная версия с лимитом 500 URL за один краул и ограниченным набором функций. Для полного функционала (JS-рендеринг, интеграции, custom extraction, cookies) нужна платная годовая лицензия.
Для чего нужен Screaming Frog?
Для технического SEO-аудита: поиска битых ссылок, редиректов, дублей Title, ошибок canonical и hreflang, проверки структурированных данных, генерации sitemap и парсинга данных. Это базовый инструмент технического SEO-специалиста.
Можно ли проверять cookies в Screaming Frog?
Да, платная версия сохраняет cookies, которые устанавливает сайт во время сканирования. Это используют для аудита согласия (GDPR), поиска cookies до согласия, аудита сторонних трекеров и доступа к контенту за логином.
Рендерит ли Screaming Frog JavaScript?
Да, в платной версии есть рендеринг через встроенный Chromium. Это позволяет корректно сканировать сайты на React, Vue и Angular, где контент появляется после выполнения JavaScript.
Сколько URL сканирует бесплатная версия?
Бесплатная версия ограничена 500 URL за один краул. Для более крупных сайтов нужна платная лицензия, которая снимает это ограничение.
Screaming Frog — инструмент, который должен быть в арсенале каждого технического SEO-специалиста. Но сам по себе краулер не улучшает позиции: значение имеет правильная интерпретация данных и приоритизация исправлений. Если вам нужен глубокий технический аудит сайта и чёткий план действий, команда Spilno Agency проведёт полную диагностику и поможет устранить ошибки, сдерживающие рост трафика.
Читайте также

ARIA-метки: что это такое и влияют ли на SEO?
ARIA-метки (от WAI-ARIA — Accessible Rich Internet Applications) — это специальные HTML-атрибуты, такие как aria-label, aria-labelledby или role,…

WebMCP: что это такое и как он работает
WebMCP (Web Model Context Protocol) — это новый стандарт, который позволяет сайту предоставить AI-агенту готовые «инструменты» для действий…

Режим согласия: как конфиденциальность данных влияет на SEO в 2026 году
Режим согласия (Consent Mode) — это механизм, который меняет поведение тегов аналитики и рекламы в зависимости от того,…